Welcome to Machine Learning Workflow
Introduction to key steps and tasks in Machine Learning
Here we discuss Machine Learning Basics, the basic steps to get started with ML, setting up an ML pipeline.
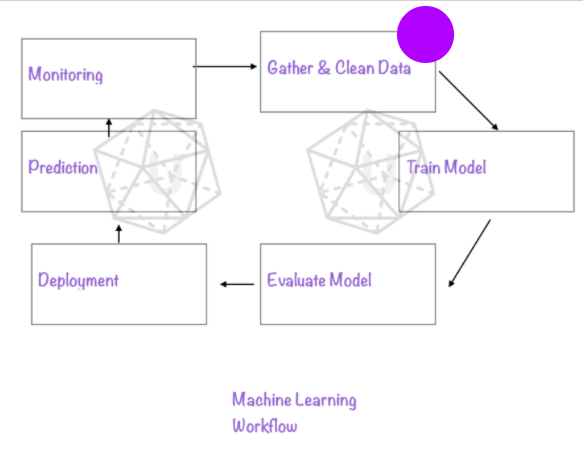
First, let's talk about the key steps of machine learning. We call that the machine learning workflow. No matter which framework, library you use, generally, this workflow serves as a good roadmap. For example, generally, machine learning engineering will start with data cleaning, preprocessing. And ends with model deployment and monitoring.
What's amazing is that this framework works well for Uber Engineering and Google Cloud ML. Check out their ML workflow charts here. Uber Machine Learning Workflow Google Machine Learning Workflow
1. Gather Data, Clean Data, Data Preprocessing
Also includes Feature Selection, Feature Engineering, Data Preparation
Read more about Data Pre-Processing, Clean - Uniqtech topic page
2. Train Model, Model Fine Tuning, Hyper Parameter Tuning
This is the phase where the model learns. In Neural Networks, weights are learned. Gradient descent, weight update.
3. Evaluating Model, evaluation metrics, model selection
In depth discussion on loss functions. How to best choose them. Measuring performance of the model, error compared to the ground truth in supervised learning.
4. Deployment
Deploy to production. Make model endpoint available as an API or loading the model locally. Optimize model for inference, mobile, or deployment.
5. Prediction
6. Monitoring
Track performance indicators over time. Prediction endpoint, API performance, testing etc. Availability, uptime. Determine if there's a need for continuous training - if data change over time.
The above high level illustration of Machine Learning workflow is similar to the workflows of major AI platforms such as Google Cloud, AWS. When studying and using new ML libraries, try to keep this framework in mind when organizing knowledge points. To summarize, machine learning is all about working with data, cleaning and formatting data into appropriate model inputs, create / select best models by trying different models and optimizing model parameters, in an iterative feedback process, or using an existing state-of-art architecture. Saving the optimal trained model, and use that for prediction. Monitor the performance of the model, re-train, maintain as needed. Optimize the model for prediction on the cloud, as an API endpoint, or on mobile devices. This a summary of common Machine Learning, Deep Learning tasks. Each stage of machine learning can be iteractive, and takes quite a bit of feedback and optimization improvement cycle.
PRO Coming soon...