Intro to Machine Learning and Deep Learning
Uniqtech Guide to Machine Learning
Author: Uniqtech Co.
This course is for informational purpose only. Its goal is to introduce machine learning to beginners. Not for commercial use, not for production use. Read full disclaimer here.
Machine Learning tutorials
We firmly believe that machine learning is for everyone. Just like we firmly believe that coding is for every one.
Machine learning versus conventional programming
Difference between machine learning and general programming
Machine learning differs from conventional programming (no need to give specific step by step control flow instruction). The model learns by updating weights.
Different models have different architecture elements.
Machine learning and deep learning can be declarative too. We tell the data and the model to move to GPU. We don’t specify how and we don’t need to know.
Declarative programming is like writing html. You just have to know what tags to use. There are control flows in our tasks but much fewer compared rule based programming.
Using deep learning libraries is also similar to using other APIs. We need to know what info it expects and what kind of info it gives back. Documentations are helpful.
Some rules and instructions are too complicated to build. For example, AlphaGO won against the GO champion who by definition knows GO the best in the world. Programmers cannot just write a program and win a match against the grandmaster.
Instead, programmers write machine learning algorithms that learn by example, like babies learn languages and concepts by perceiving the world, from all the grandmasters. All the rules and moves are produced by the algorithm on the fly. There's no pre-written rule book.
That's fascinating to know machine learning can solve problems that may be too hard for humans. It can derive a solution when we have no idea how to get started. The same algorithm can be easily modified to learn different games, puzzles, competitions: GO, Battlefield, Chess, ...
It sounds complex but getting started with machine learning is relatively easy. That's what these tutorials and youtube videos are about!
There are three major areas of machine learning : supervised learning, unsupervised learning, reinforcement learning (robotics, agents).
There are two arch types of machine learning : 01 classical machine learning 02 deep learning.
Depends on the data type of the predicted, we will also need to select models specialized in regression (predicted value is numeric, continuous) or classification (predicted class/label is categorical, discrete).
This will be discussed again later.
Supervised learning training data comes with the feature and label, for example a tweet associated with a positive / negative sentiment 1,0.
Read about features and labels here : Feature, ML glossary list
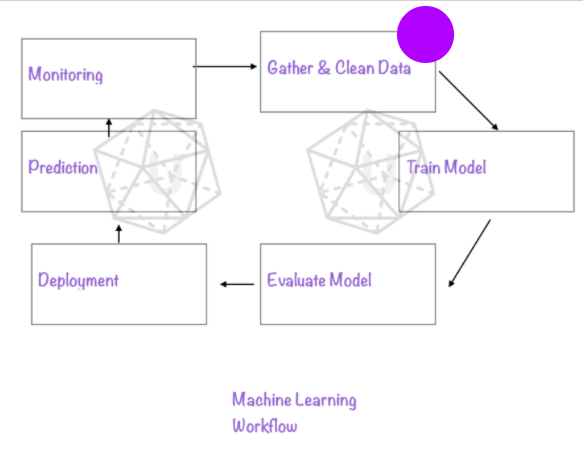
Machine Learning Workflow
Key machine learning steps, processes in a diagram. workflow flash card
Another way to think about Machine Learning is XKCD's comic about machine learning. Which sums it up extremely well, with humor. XKCD Machine Learning joke.
Check out another version of the ML workflow chart here : Machine Learning Workflow (Google Cloud ML workflow)
Our model takes in inputs and process them through a stack of layers and then returns the outputs.
(inputs --> machine learning model --> outputs)
There are two major tasks in machine learning: 01 train model with training data, 02 use model to make predictions.
Basic Neural Network
Regular neural networks or neural nets are made of neurons and hidden layers and a fully connected last layer.
A neuron is the smallest component (smallest building block) in a neural network (nn). The early version of a neural network is a perceptron, a network of neurons.
There are other types of neural networks such as convolutional neural networks (CNN).
Regular nn takes vectors as inputs. Each layer has independent weights, which are not shared across any layers. CNN has shared weights. It expects an image as input.
Hidden layer is an inner layer of neural network layer made of neurons.
Fully connected refer to the fact that each neuron in one layer is connected to each other neuron in the previous layer.
For example, if layer 00 has 5 neurons, and layer 01 has 10 neurons, there will be 5x10 = 50 connections.
That number becomes large quickly, hence later, smaller connections are invented.
According to Stanford class, fully connected nn doesn't scale well to image. Each simple image data like CIFAR-10, we will need 32x32x3 = 3072 weights in a
simple neural network. 32 pixel by 32 pixel by 3 color channels.
The simple way to write a model is to use a Sequential, a wrapper for model layers and components. What is a Sequential? Another way is to use objected oriented programming (OOP).
More content coming soon…
Data Preprocessing Data Cleaning
Aka data preparation, data cleaning for machine learning.
Raw data contains noises, unclean data, errors. Remove duplication in rows, as well as columns.
Read our full data cleaning, data preprocessing - Uniqtech guide here
The most important task is to convert real world data into numeric data. Machine learning Models expects numeric data as input.
They do not natively understand how to read files, process image data, ...
This is called the vectorization of data.
Generally, we clean and denoise real world data, convert it into multi dimensional matrices - vector representation of the data.
We have many articles about how this works. Message us to get more details. Our check out our substack newsletters
uniqtech.substack.com
Train Test Split
Train test split is a very important first step of the machine learning work flow. It prevents overfitting.
We will need to split input data into train, test dataset, as well as a third validation dataset.
Models, neural networks are great at discovering and even memorizing patterns. If we don't shuffle and split data,
they can easily learn some latent patterns based on how the files, data and folders are organized.
train test split basics [flash card]
train test split basics 02 [flash card]
train test split explained [pro, member, flash card] Learn more about the function on the official doc here
Official document train test split
# import library
from sklearn.model_selection import train_test_split
# split and return a tuple of 4
# unpack using comma notation into X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)
Activation Functions
Activation functions give our neural networks the ability to model non-linear data.
In turn, our model can model complex patterns.
Prior math operations are mostly linear algebra, great for modeling lines, planes.
In real life, patterns are often non-linear. Some patterns are impossible to separate linearly.
Uniqtech's general guide to activation functions
Uniqtech Guide Softmax activation function This is one of our most cited articles ever.
Uniqtech Guide Intermediate Softmax [activation function, medium]
An Overview of Activation Function in Deep Learning - Uniqtech Guide
Evaluating Performance
Calculate Error, Scoring Model, Calculating Loss, Writing Custom Loss Functions
We said this before: because ML and Deep Learning are multi-disciplinary fields, we have legacy vocabulary from every study discipline possible. They can refer to the same thing, but also differ by nuance. Some way to evaluate model performance is to calculate accuracy, error function, custom error function, aka loss function, metrics, scoring...
Here's a basic difference between ground truth and prediction error = y - y_hat Basic error function As mentioned in this flash card, we often add more math on top of the simple difference help our model perform better and generalize better. Here's some additional discussion.
In our tutorials we will learn how to read formula fast and understand how to implement some of these seemingly complicated patterns.
We are made famous by our softmax formula explanation Uniqtech Softmax Tutorial on Medium. It's gotten so famous that it's being cited in scholarly publications around the world : glad to have helped mangroves, NLP and health care from San Jose, to Asia to Nordic countries.
The important thing to understand is : if you are not using multiclass classification you won't need Softmax. Each of the error / loss function has its strength and weakness making each suitable for very different tasks. A good machine learnist is someone who understands this nuance.
Evaluating Models, Model Selection
Intro
Depends on the machine learning task and model we will need to choose different metrics to evaluate it. Metrics can measure distance between prediction and ground truth (e.g. y_pred-y).
Used for quantifying errors, minimize error. Measure goodness of fit. Used for choosing models - Model Selection.
Metrics can also be called error function, cost function, scoring metric, scoring function (sklearn), distance function. `from sklearn.metrics import{ arc, confusion_matrix, roc_auc_score, roc_curve}`.
Well tested models can generalize better - performings better in real life.
This is intro to metrics also a flash card.
Two common, introductory ways to evaluate models is to use Euclidean Distance function for regression and cross entropy loss for classification tasks (categoric data).
Here's our medium article on Uniqtech's Guide to Euclidean Distance vs Manhattan Distance Functions for Regression.
Here's our medium article on Uniqtech's Guide to Cross Entropy Loss Function
Our pro members can read these articles for free. Just message us on the Message tab to get a copy. We will also send you all kinds of PDF goodies such as top cheat sheets and tech notes.
You can also sign up to be Medium members using our link Become a Medium.com member. Many awesome authors and developers publish on medium.
Different distance function can be used as the similarity measures - how similar is our prediction from the ground truth. The choice of distance function, similarity measures depend on the goal of the model and the task at hand.
Regularization
regularization prevents overfitting, helps models generalize better - perform better on real life datasets or previously unseen datasets. Prevents models from being clever, memorizing or gaming the results. L1 L2 Regularization - Uniqtech Guide [medium]
Additional topics
Train test validation split
A quick reminder, data needs to be preprocessed and split. Since we will spend many future tutorials on data processing we will revisit it in the future. Data should be split into three randomized / shuffled / stratified datasets : train, test, validation.
Data for training and selecting machine learning models are split into three parts: 1) training data 2) data used for testing metrics, model selection 3) hold-out dataset that mimics real world data, used last.
`train_test_split()` function is used during the data cleaning phase of the machine learning workflow.
Some refer to validation as test. The first dataset - train is for training the model and updating weights. Models learn by tuning weights and then check answers. It is important to remember whatever the second dataset is called, it is used for testing models and making adjustments and testing performance. The final dataset is for mimicking real world data so it much be representative. It must be a hold out dataset - the model must not have ever seen the data until it is nearly completely done, trained and ready for the final sanity check. Machine learning models are so powerful they can obtain “leaks” from data it has seen at any given time. It may become a bias of the model and decrease its ability to generalize.
Feature Selection
Calculate feature importance. Feature Importance
More resources
Debugging Machine Learning Code [Medium] Uniqtech Guide
Loading practice datasets | Load Build-in Datasets | Load toy datasets
Chinese English Machine Learning Dictionary
Machine Learning Training Loop Code Patterns - Uniqtech Guide
Choice of distance function: What is training? Training is the learning part of "machine learning". In iterative processes, your models compare predictions (y_hat) with ground truth (y) in supervised learning. Then it will compute a heuristic of distance, which represents how good or far off is the prediction, also represents how distant is the prediction from the ground truth. Depends on the metrics chosen, the distance result in very different numbers. There are strengths and weaknesses of each distance function, making each of them suitable for different tasks. There's no one magical distance function. An example of distance function in regression is euclidean distance. An example of distance function in classification is multi-class cross-entropy. In some scenarios, when comparing two vectors, their dot product can be used as the distance function. The choice of distance function takes trial and error. And can be an art.
Training is an iterative process. During the process, we use tools such as auto grad gradient compute, gradient descent, optimizer, momentum, learning rate... all kinds of models, algorithms, formula, and parameters to guide us closer to the optimal model with optimal weights(parameters). It's an art form. Often trial and error is needed. Random starts are faster. Making educated guesses of next steps(next descent) can generate good results and save time. Common types of optimizers [pro]
Training models is a art form. Other than data preprocessing, training is where the bulk of machine learning effort, costs and technical skills are invested in.
Using .fit() API In some machine learning and deep learning libraries, you can just call my_model_var_name.fit(X_train, y_train). The .fit() method (out-of-box API) does not require you to write a custom training loop from scratch.
The above is a common pattern in scikit-learn. It’s as simple as give the fit method the training data aka features and training labels (big matrix X and small vector y).
Similarly in Tensorflow, you can also use .fit() the interface name is the same but implementation details differ between libraries and between models.
For example, the actual under-the-hood method of training is very differente for support vector machines versus tree-based models, versus neural networks.
The fit API abstracts these implementation and technical details from developers.
In other words, the model class will determine how the .fit() method actually runs. This is a nice abstraction for users. Users don't need to worry about what's under the hood. But what if the user wants to customize?
Under the hood, models do very different things for tree based algorithms versus support vector machines (SVN). In scikit learn (a classical ML library), nearly all training interface is called fit.
See our Pytorch Custom Training Loop - Uniqtech Guide
Sklearn Scikit Learn Example
High level API scikit learn tensorflow .fit() is an example of code abstraction at work. User doesn't need to know how training is implemented for each classical machine learning model. User just have to call fit. sklearn.fit(X_train, y_train) fit training dataset feature matrix big X with the prediction vector small y. Scikit-Learn Machine Learning Pattern (training loop using fit)
An Overview of Machine Learning Tools and Libraries
Machine Learning, Deep Learning tools and library [PRO]
Grad School
US News maintains annual ranking of US computer science programs. Here's an example of information science. Note: the top universities for data science is not neccessarily Stanford, Harvard.
Data Science with R Programming Language
Data cleaning in R (easter egg, ebook, pro access only) Data cleaning in R [PRO]
Getting started with Natural Language Processing (NLP)
Our guide to getting started with Natural Language Processing. Member can request Medium article PDFs or texts to read offline. NLP basics, vocabulary, terminology
Uniqtech Comprehensive Guide to Deep Learning on AWS
Performance
Improving performance often means preventing overfitting, and reducing model bias - choosing the best model for the task. Cross Validation
Famous People in Machine Learning
Machine Learning Who's Who
Mini documentary of Geoffrey Hinton Machine Learning Who's Who by Uniqtech
Additional resources: Pytorch, Uniqtech's Guide to getting started with.
Data scientists and data engineers often have to work with data files on the computer or in the cloud. Bash command line, console, scripting skills come handy. Learn how to work with terminals using our guide to
Bash Command Line Cheat Sheet for Data Scientists - Uniqtech Guide
An Overview of Scikit-Learn sklearn machine learning code snippet - Uniqtech Guide
Uniqtech Guide to Pytorch This guide was featured on KDNuggets Uniqtech's Guide to Pytorch on KDNuggets
Additional Resource: Anaconda, Uniqtech's Guide to setting up data science environment
Our guide, cheat sheet to set up the anaconda data science environment and command line code for anaconda. Uniqtech's Guide to Anaconda and Miniconda [Medium, Installation, Data Science Environment]
Getting Started with Computer Vision [additional resource]
Computer Vision - Uniqtech Guide
Famous Machine Learning Datasets - Uniqtech medium post Uniqtech Guide to ML datasets on Medium
Traditional Machine Learning
Statistical Model, Probability Model
Edge Compute
AI on the edge | Edge Compute | Portable Machine Learning Hardware
Portable AI Hardware